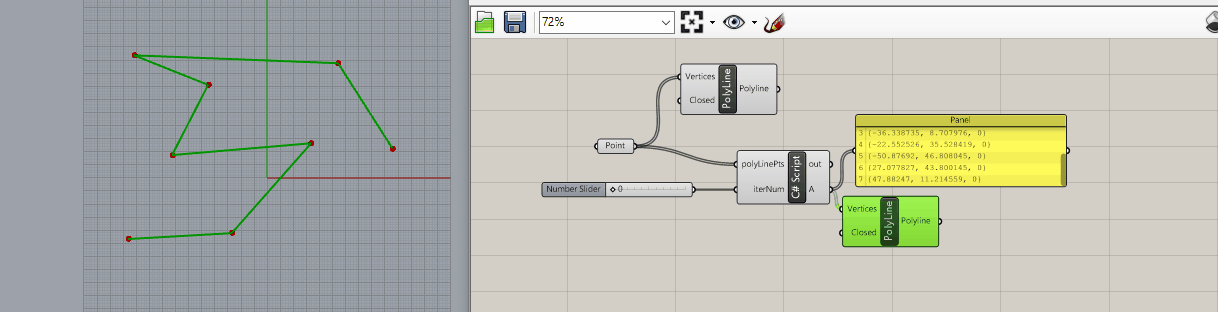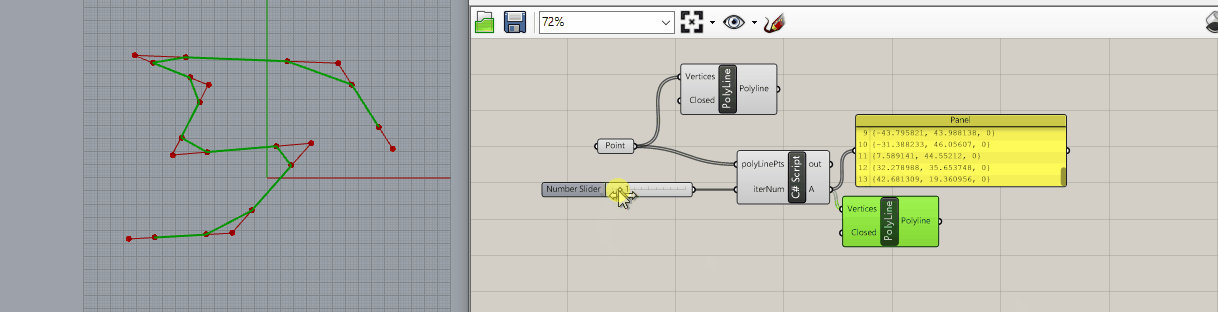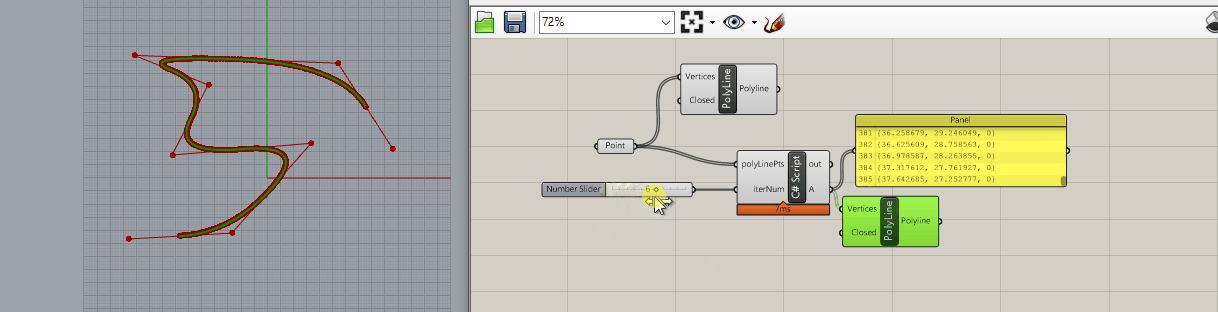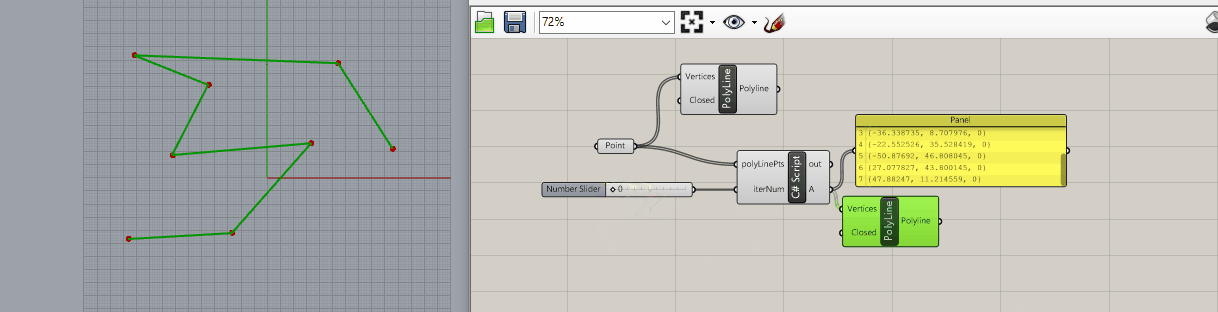
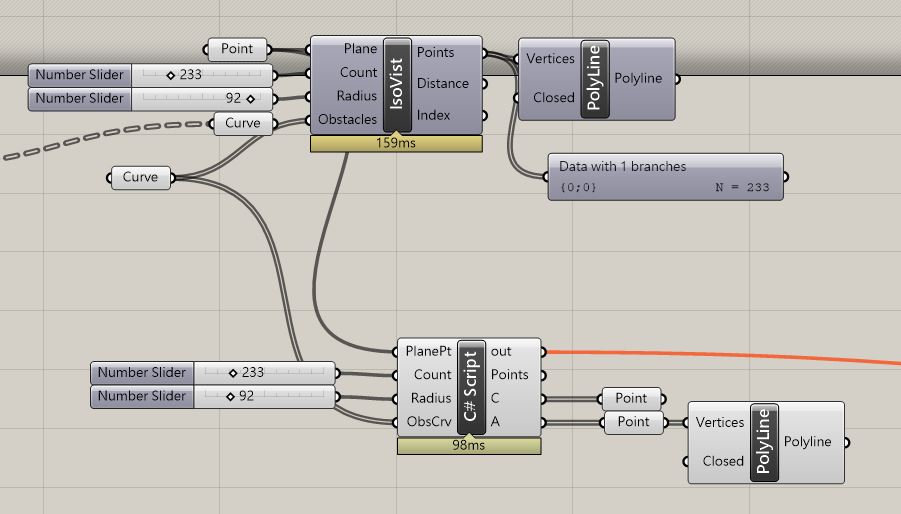
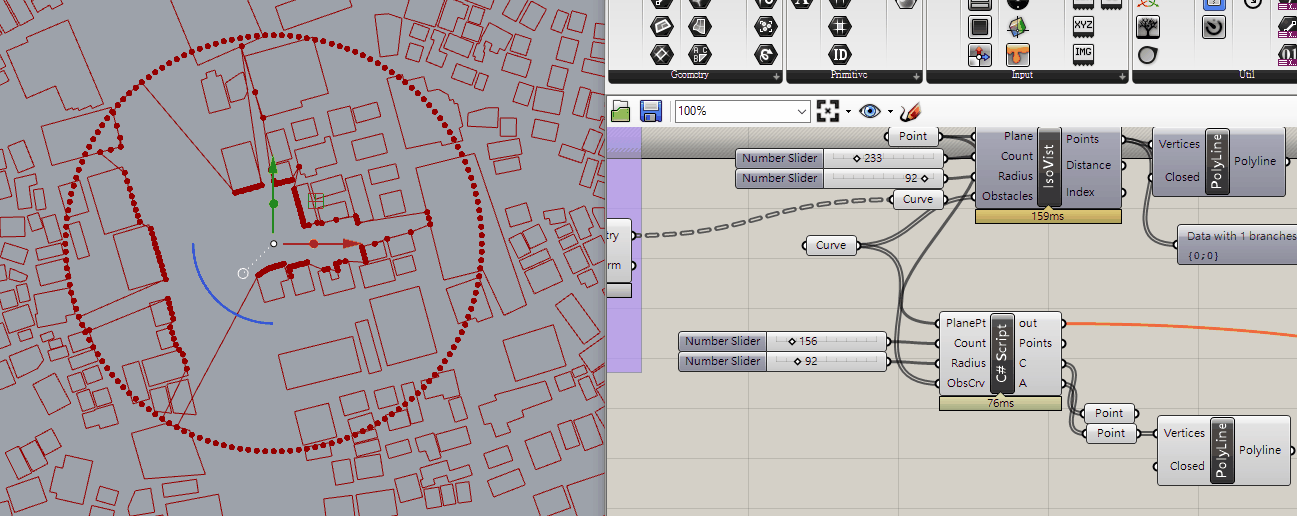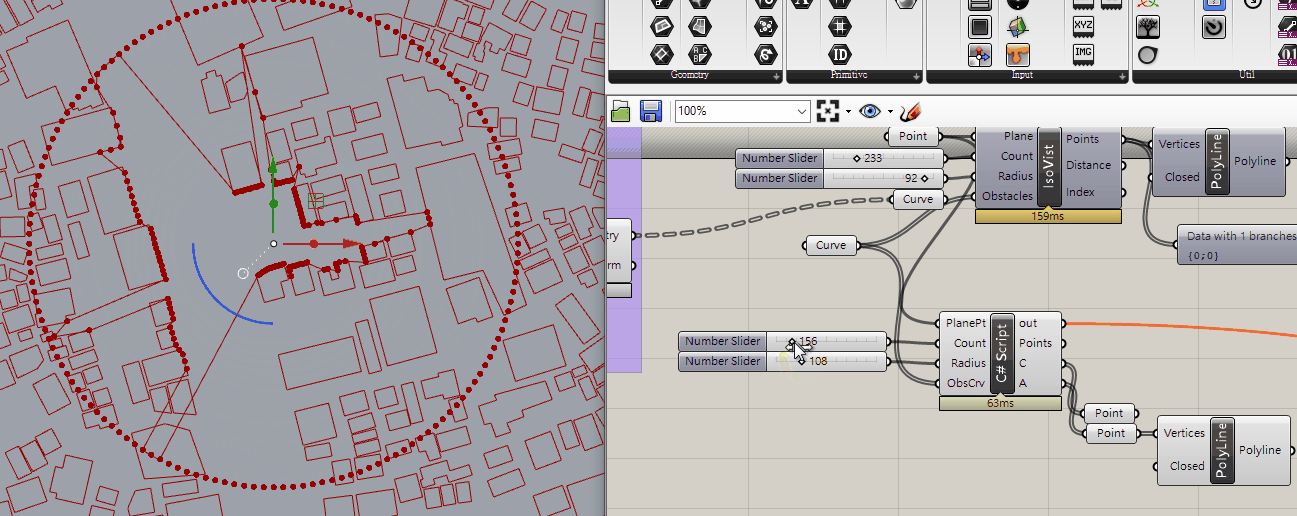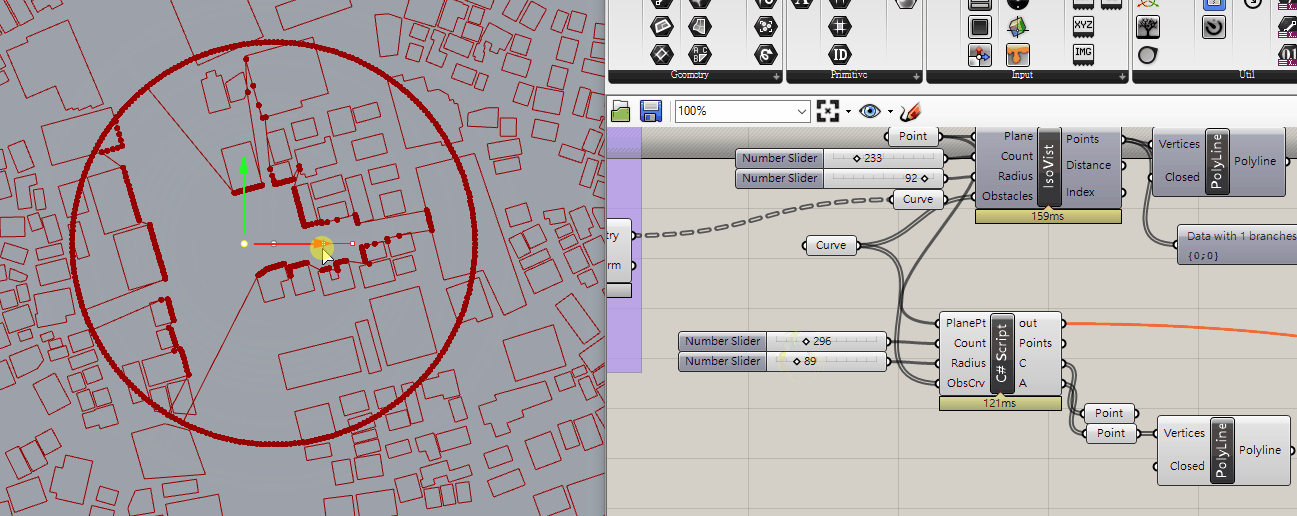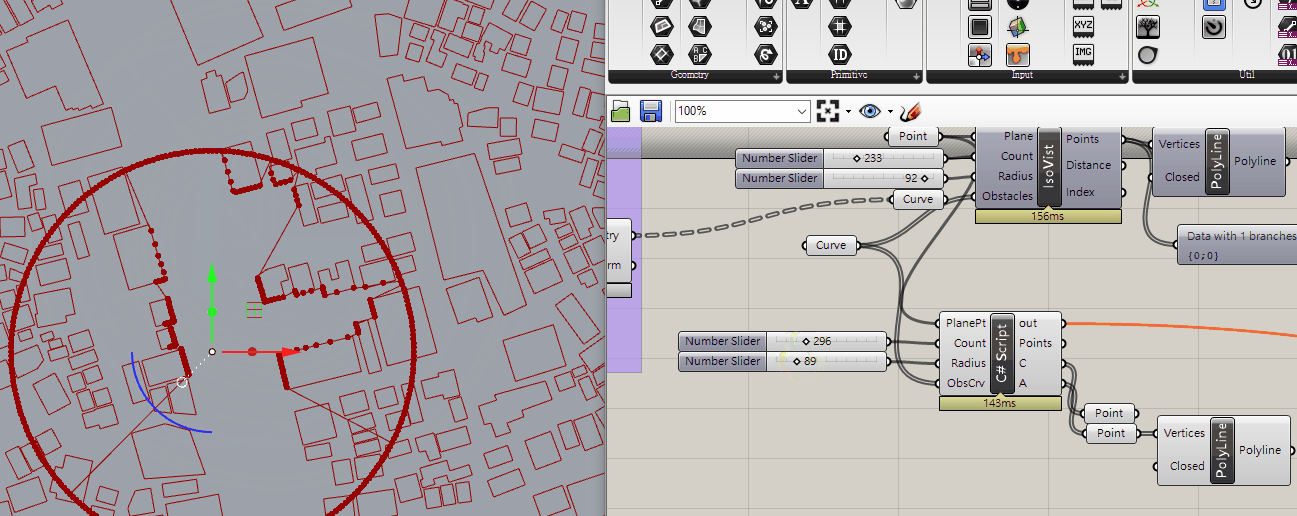
There are 2 goals of partitions into convex pieces
- parition a polygon into as few convex pieces as possible
- do so as quickly as possible
Two types of partition of a polygon P may be distingusihed
- a partition by
diagonals (endpoints must be vertices)
- a partition by
segments (endpoints need lie on $\partial P$)
The distinction is that diagonal endpoints must be vertices, whereas segment endpoints need lie on $\partial P$
Optimum Partition
To evalute the efficiency of partitions, it is useful to have bounds on the best possible partition.
Theorem 2.5.1(Chazelle)
Let $\phi$ be the fewest number of convex pieces into which a polygon may be partitioned.
For a polygon of r reflex vertices,
Reflex vertice:
In a polygon, a vertex is called “convex“ if the internal angle of the polygon is less the $\pi$ randians; otherwise, it is called “concave“ or “reflex“
Hertel and Mehlhorn Algorithm
Hertel & Melhorn (1983) found a very clean algorithm that partitions with diagonals quickly and has bounded “badness” in terms of the number of convex pieces.
In some convex partition of a polygon by diagonals, call a diagonal d is essential vertex v if removal of d creates a piece that is nonconvex at v.
Clearly if d is essential it must be incident to v, and v must be reflexed.
A diagonal that is not essential for either of its endpoints is called inessential
Hertel and Mehlhorn’s algorithm is simply this:
Satrt with a trinagulation of P; remove an inessential diagonal; repeat.
Clearly this algorithm results in a partition of P by diagonals into convex pieces.
It can be accomplished in linear time with the use of appropriate data structure. So the only issue is how far from the optimum might it be.
Lemma 2.5.2
There can be at most two diagonals essential for any reflex vertex
Philipp Kindermann
Part. a Polygon into Monotone Pieces
Idea: Classify vertices of given simple polygon P
- turn vertices:
- start vertex
- split vertex
- end vertex
- merge vertex
- regular vertices
Lemma.
Let P be a simple polygon. Then P is y-monotone <-> P has neither split vertices nor merge vertices
The idea here is try to destory
- split vertices
- merge vertices
Problem: Diagonals must not cross